The Burst Demand Crisis¶
I spend a lot of time with engineering leaders and developer infrastructure teams. Over the past six months, a pattern has been emerging: build queues are experiencing demand in bursts, not waves.
Last week alone, conversations in Sydney, Chicago, Los Angeles, and San Francisco all surfaced the same story:
- Sunday: A customer running EngFlow Bazel RBE at 100,000+ cores wants to triple capacity over the next year. PR volume is surging with no sign of slowing.
- Monday: Prospective customer's CI queue is in crisis. Engineering attention diverted from product work. First-time inquiry about RBE.
- Tuesday: Existing customer tried sharding load across more CI workers. Result: higher cloud costs, same bottleneck. Needs help making workloads RBE-compatible.
- Thursday: A large enterprise customer skipped our customer dinner - they were occupied with urgent internal testing, preparing to double their RBE load.
- Friday: Reviewed load planning with a customer preparing for an AI generation hackathon - forecasting what their infrastructure must absorb in the coming months.
This is the Burst Demand Crisis. AI coding assistants have decoupled code production volume from engineering headcount. A team of 50 engineers with AI pair programmers can generate the PR volume of 500, in sudden and concentrated bursts. Several of our customers have seen PR volume has quadrupled since January. The familiar model of steady commit flow, predictable queues, and linear growth is old news.
The build graph efficiency opportunity¶
You can't throw compute at a graph efficiency problem and expect a proportional return.
When queues back up, the instinct is to scale horizontally: more workers, more cloud compute. We've watched this fail repeatedly. Cloud provider stockouts at these scales are real. Burst pricing is punishing. And neither solves the actual problem.
Most enterprise build graphs carry years of accumulated inefficiency: redundant actions, overly broad dependencies, and test suites that re-run far more than necessary. When AI multiplies your PR volume 4× in a quarter, every percentage point of that waste compounds. You can't throw compute at a graph efficiency problem and expect a proportional return.
How EngFlow solves this¶
EngFlow is a customer value-led business. We function as an extension of our customers' Developer Experience teams: in shared Slack channels, onsite when needed for collaborative efficiency improvements, reviewing build forensics together, co-owning capacity roadmaps ahead of hackathons, product launches, and AI generation sprints.
That operational closeness is what makes the intelligence loop work. We're uniquely positioned to see patterns across hundreds of thousands of cores and dozens of enterprise-scale workloads simultaneously. EngFlow also has the largest concentration of Bazel creators, experts, and contributors of any company in the world - we've designed its internals, written its core execution model, and scaled it at Google. That combination of expertise, field depth and our EngFlow platform is what makes our recommendations actionable.
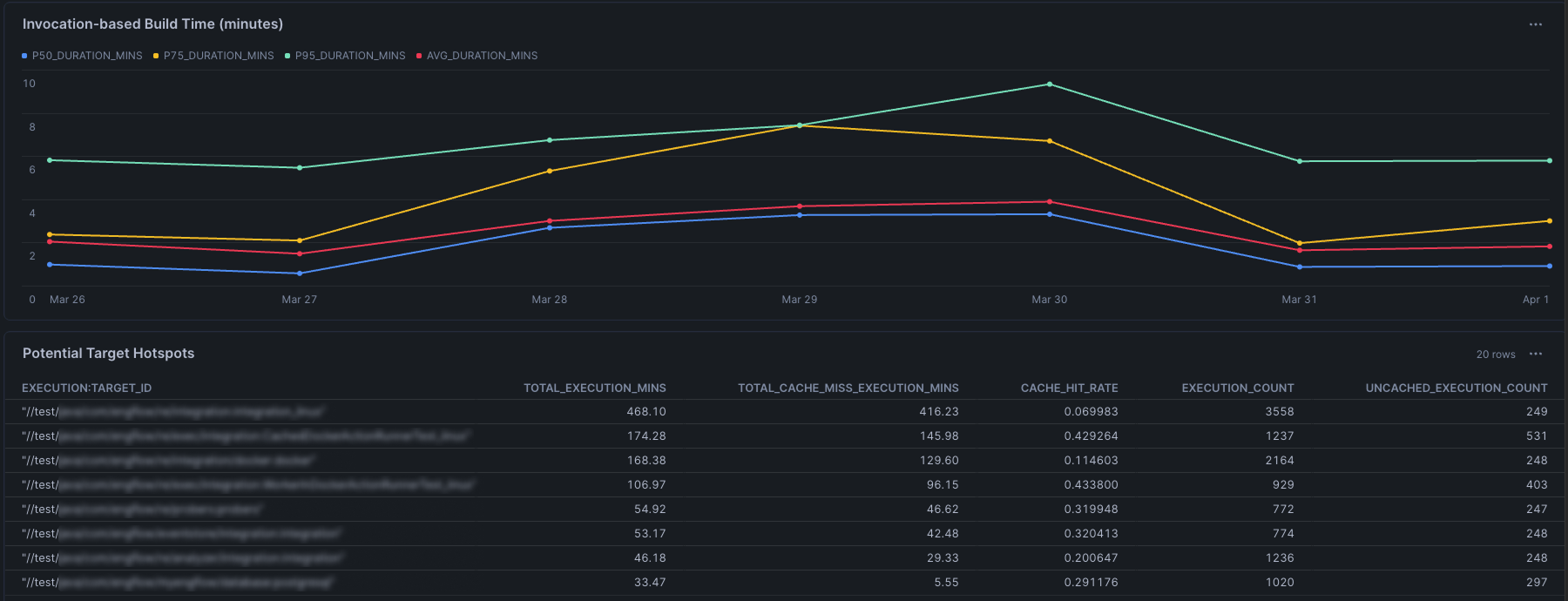
Last month, we used EngFlow Build Forensics to analyze a customer's build data, identifying hotspots, redundant actions, and bottlenecks. We helped our customer:
- Eliminate redundant actions executing on every build due to overly broad dependency declarations.
- Apply intelligent test selection, running only tests genuinely affected by each change rather than the full suite.
- Reorder execution to minimize the critical path, pushing more work into parallel lanes.
The result: a 50% reduction in build duration at p90 and p95 - not by adding cores, but by acting on the insights surfaced using EngFlow Build Forensics. The ability to discover target-level information across multiple customizable dimensions - execution time, cache hit rate, build frequency - is just a query away. With EngFlow, our customers are able to absorb bursts more gracefully, giving teams the headroom to scale with AI rather than scramble against it.
Scaling smarter¶
EngFlow operates the largest Bazel remote execution deployments outside Google, spanning hundreds of thousands of cores across some of the world's most demanding engineering organizations, including ARM, Block, BMW, Canva, Databricks, Lyft, Perplexity, Snap, and Zoox.
As this scale continues to push the limits of our customers, cloud providers, and our own infrastructure, our focus is on three things:
- Parallelizing more: Identifying where the build graph serializes work that could be distributed, and advising customers on restructuring it to use provisioned cores more effectively.
- Reducing compute required: Through build graph analysis and recommendations that eliminate redundant work before it ever runs, and through continuous optimizations in resource allocation and action behavior, which so far resulted in EngFlow requiring up to 50% less compute than competing options.
- Investing in the Bazel ecosystem: Making rules more scalable so that as code volume increases, the foundational infrastructure scales with it.
What's next¶
Agentic development workflows. AI agents running build-test-fix cycles at machine speed will create load profiles that look nothing like human developer patterns. The enterprises ready for that world are partnering with EngFlow on having a scalable foundational infrastructure built on graph intelligence.
If your teams are entering the Burst Demand era with plans for significant AI-driven code volume growth and ever-growing CI queue pressure, we'd love to chat! Visit engflow.com/contact or find us on LinkedIn.