Running CMake at scale¶
The main service we provide at EngFlow is Remote Execution (or RE for short). Remote Execution allows a build to run over a horizontally-scalable distributed system, thus speeding up highly parallelized builds. This parallelization is one of the features that make Bazel builds so scalable. Outside of Bazel, Buck2 and a few exotic build systems such as Chromium and AOSP, the adoption of this protocol is almost non-existent. Here at EngFlow we saw many C and C++ codebases successfully adopting RE, and decided to partner with tipi.build, experts in that field, to bring CMake support to EngFlow.
Why not use distcc and ccache?¶
distcc sits at the compiler level, essentially remoting each individual compiler invocation for each individual source file. This has many drawbacks, ranging from increased network latency, to careful and complex configuration if one wants to guarantee build reproducibility.
This encourages developer teams to relegate distcc only to CI. Because of the way distcc and ccache download each individual cache entry it also requires the CI machine to always be on, which is incompatible with modern major cloud CI services, that always provides a clean machine on build start.
CMake RE takes a different approach, sitting at the build system level. When a user invokes CMake RE, the full build is executed remotely in an ephemeral and reproducible environment.
How does RE work?¶
Remote Execution is a simple protocol that allows a build tool to handle inputs and outputs, and optionally run a command in an ephemeral execution environment. Every time a build tool needs to run a command, like invoking a compiler, instead of executing it locally, it can use remote execution to execute it faster elsewhere. The workflow varies by implementation, but usually looks something like this:
- Construct a command and check by its digest if it has been already executed and its output cached
- If the outputs are already cached then they can be optionally downloaded
- Otherwise, check if the inputs of a command are all present and otherwise upload the missing files
- Run the command and optionally download its outputs
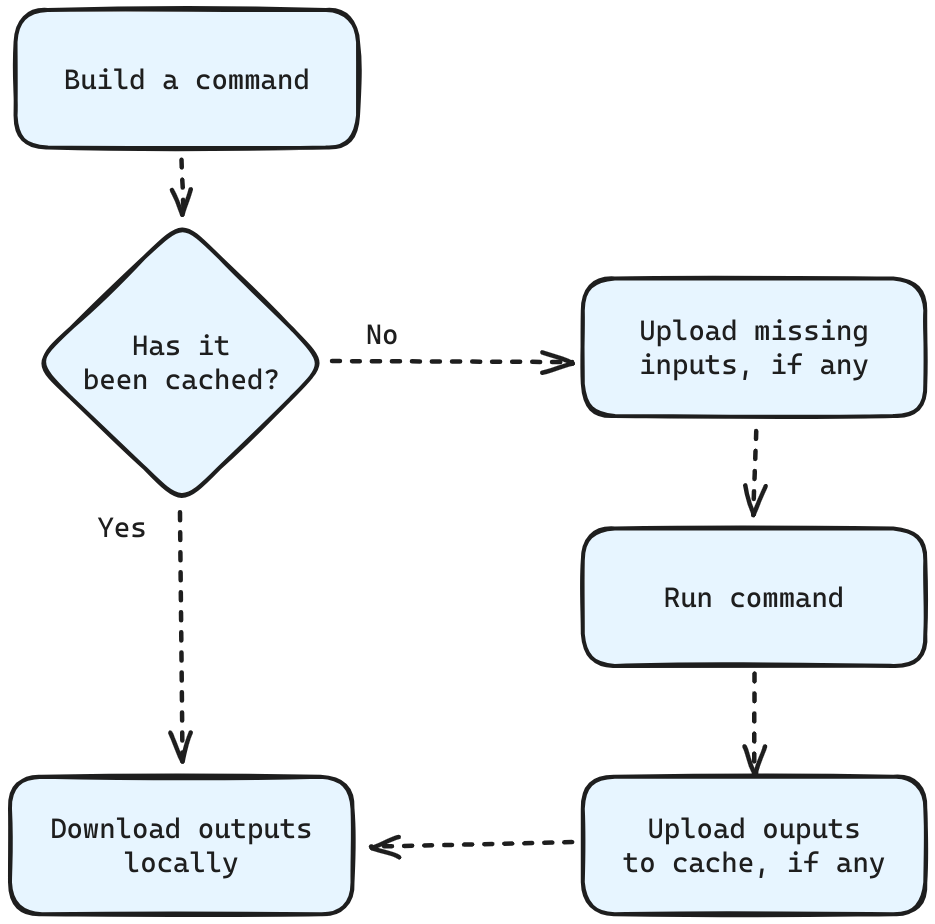
This is similar to how local build systems work. However, there are a few challenges with this approach when using it remotely.
Running compilation and linking remotely¶
The first problem we face when trying to run builds using RE is that each and every command the build wants to run remotely needs to fully capture its inputs and expected outputs. This is easy with Bazel, as both inputs and outputs are specified in the build configuration, but with CMake, and most other build systems, that information is not specified. When it comes to compilation though there is a tool that can help us: Goma.
Goma is a tool that wraps the compiler (similarly to distcc/icecc) but uses the RE protocol under the hood. It infers inputs and expected outputs of a compilation unit, and then sends the compilation command to RE. We picked Goma because we had plenty of experience running it in production. Reclient, Google's new solution to this problem, had not been open-sourced yet. We also decided not to use recc, as we would be constrained to C and C++ codebases, whereas we think we could support a much larger number of platforms in the future.
Goma runs a long-lived process called compiler-proxy that talks to a remote goma instance called remoteexec-proxy that communicates with EngFlow's RE. A user only needs to start an instance of compiler-proxy and invoke the compiler-wrapper gomacc, which then invokes a RPC on compiler-proxy. Once this process starts, goma discovers the inputs of a command and tries to run it remotely, falling back to local execution if it cannot. Alternative goma can also race local and remote execution which can in some cases make builds even faster!
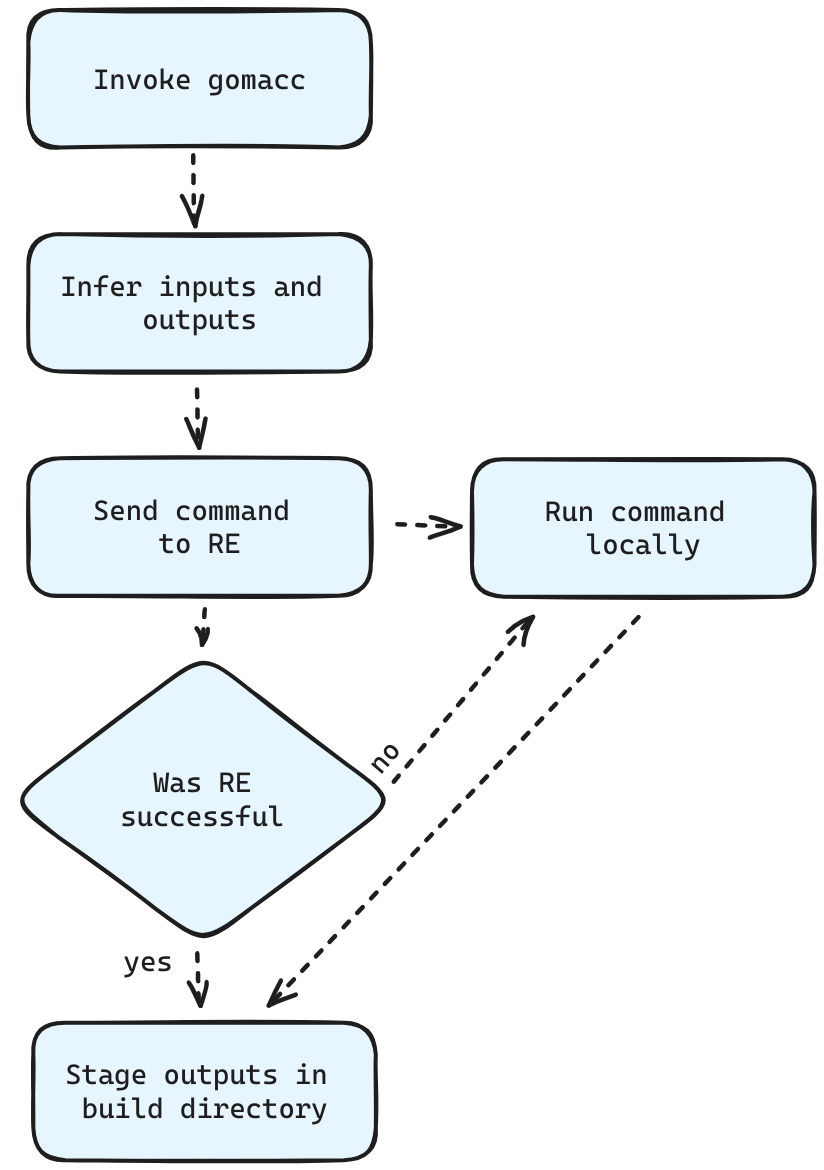
Finally, this very same tool supports linking, so we can also use remote linking for free.
Running custom targets remotely¶
With compilations and linking out of the way, we are now left with all the custom build rules in CMake, like the ones using add_custom_command, where predicting inputs and outputs automatically is not really possible.
This is because unlike with compilation and linking, we have no control over what commands the user can write. To address this limitation, we decided to adopt a two-stage remote execution approach.
The first stage is a single large instance running on the same cluster as RE, to run all the targets that cannot be executed on RE, so anything that isn’t a compiler or linker invocation.
This instance is similar to your local developer workstation, is dynamically sized to satisfy the level of parallelism requested by the -j value, and does not need to follow the same constraints as RE.
The second stage is the one used for compilations and linking. This allows us to horizontally scale to thousands of cores whilst still being able to vertically scale all the other targets, albeit to a lower degree.
Another advantage to this approach is that it reduces the burden on the network. It allows us to store all the build outputs and intermediate artifacts remotely and only download them on demand. This takes advantage of EngFlow's remote target level caching, and tipi's first layer of git history cache, to further minimize network usage.
How to configure a RE executor¶
Because RE provides ephemeral remote executors, the build system cannot rely on the presence of any of your usual system installed tools, compilers and libraries. Without your local setup, even a small hello-world build like the following would fail due to lack of a compiler installed on the system:
| CMakeLists.txt | |
|---|---|
To make sure the remote build works, we need a mechanism to tell a RE executor how to configure an equivalent setup. Bazel's approach to this problem has traditionally been to declare tools as inputs of a command as well, but this would be really hard to retroactively fit into CMake. Instead, we use container images. Not only are OCI images almost universally-known at this point, but they make it easier to translate a workstation setup into a more reproducible environment. For this we can use CMake’s toolchains, which are made easier by tipi’s ability to inject a custom environment:
| .tipi/env | |
|---|---|
What's next?¶
Scalability in builds is a very complex problem. It's not only concerned with speed and reproducibility, it also requires a heavy investment in debuggability and observability.
Bazel already has great support for both through a protocol called Build Event Protocol (or BEP for short). This protocol is what we use in EngFlow to gather the data we need to display in the Build and Test UI. This would be a good first step into improving UX for CMake, especially with RE in the picture, which makes debugging a bit harder.
Another interesting avenue to explore is Google's newly released Reclient, which is similar to Goma, but with the added advantage of being simpler architecturally, and supporting a plethora of other languages out of the box! Not only that but it can be easily extended to support other tools.
It's still early days for Cmake RE, join our beta program to help us improve the product and decide on its future direction. We'd love to hear more from you, either as a beta-user or just as a curious developer who just stumbled on this article!